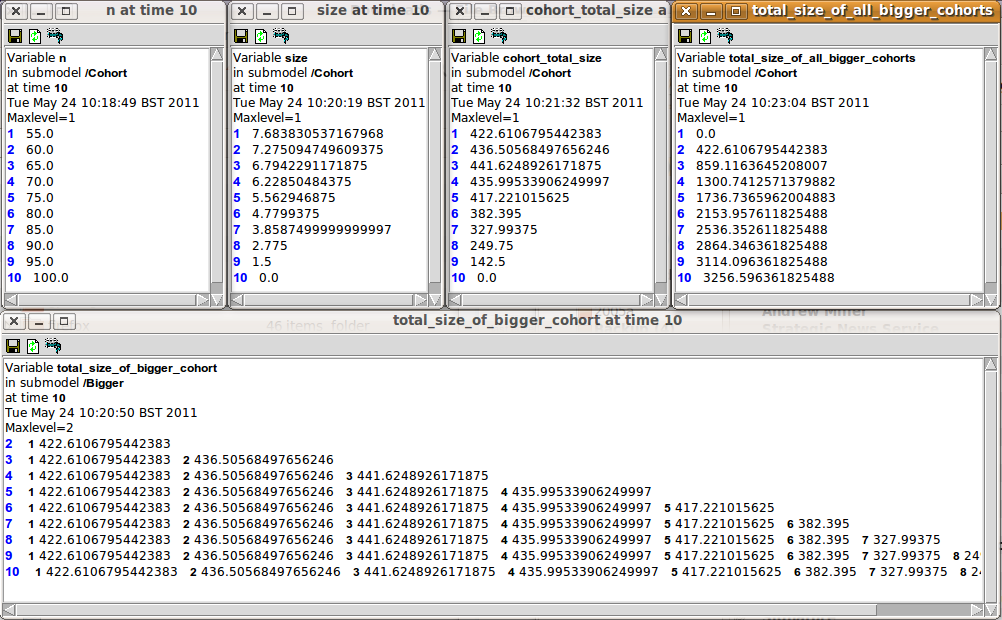
Variable: n_total = sum({n})
Where: {n} = Cohort/n
Variable: population_total_size = sum({cohort_total_size})
Where: {cohort_total_size} = Cohort/cohort_total_size
--------------------------------------------------------------
Submodel Bigger
Submodel "Bigger" is an association submodel between "Cohort" and itself with roles "other" and "me".
Condition: condition = other_size>me_size
Where:
me_size = Value(s) of ../Cohort/size from submodel "Cohort" in role "me"
other_size = Value(s) of ../Cohort/size from submodel "Cohort" in role "other"
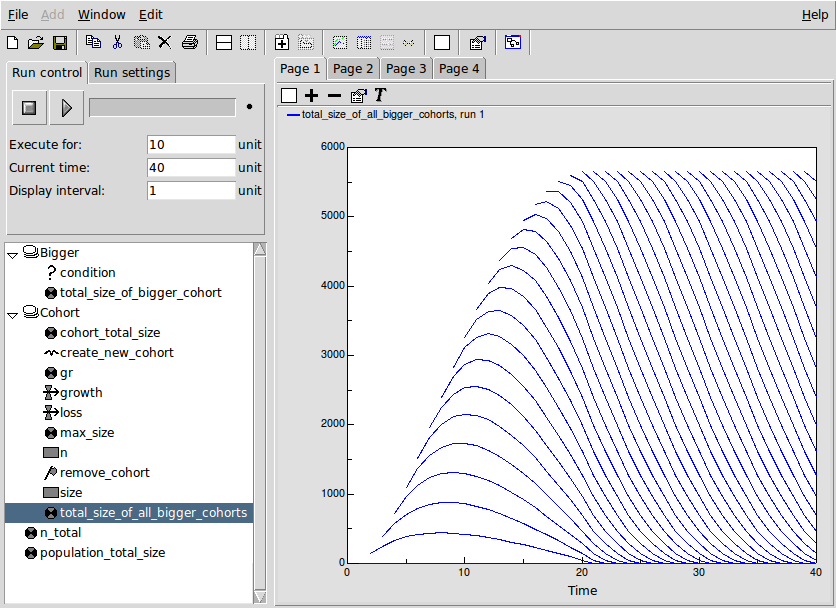
Variable: total_size_of_bigger_cohort = other_cohort_total_size
Where:
me_cohort_total_size = Value(s) of ../Cohort/cohort_total_size from submodel "Cohort" in role "me"
other_cohort_total_size = Value(s) of ../Cohort/cohort_total_size from submodel "Cohort" in role "other"
-------------------------------------------------------------------------
Submodel Cohort
Submodel "Cohort" is a population submodel.
Compartment: n
Initial value = 100
Rate of change = - loss
Compartment: size
Initial value = 0
Rate of change = + growth
Flow: growth = gr*(1-size/max_size)
Flow: loss = 5
Immigration: create_new_cohort = 1
Loss: remove_cohort = n<=0
Variable: cohort_total_size = n*size
Variable: gr = 1.5
Variable: max_size = 10
Variable: total_size_of_all_bigger_cohorts = sum({cohort_total_size_of_bigger_me})
Where:
{cohort_total_size_of_bigger_me} = ../Bigger/total_size_of_bigger_cohort for submodel "Cohort" in role "me"