Case studies
When people first see Simile’s intuitive interface, they assume it was developed for use in teaching. Not so. The prime motivation was – and still is – to meet the needs of the ecological and environmental research communities. Any modelling environment that sets out to do this must be:
- expressive, to capture the wide range of concepts use in ecological and environmental modelling, such as spatial modelling, individual-based modelling and human decision-making;
- powerful, to handle the large, complex models developed in these fields, large and complex both in terms of the number of equations and the degree of disggregation; and
- intuitive and transparent, to make it easier for researchers to build models and communicate them to others.
To demonstrate Simile’s suitability for research-grade modelling, we introduce here two major international research programmes in which Simile has played a leading role. More information can be found by following the links.
If you are involved in a research project, and see a role for Simile within that project, please contact us. We are always happy to discuss possible collaboration.
FLORES: Flexible, Land-use Oriented Resource Envisioning System
FLORES is an international programme of research which aims to improve the livelihood of the rural poor at the forest margin, through the development of models that can be used to assess the likely i mpact of alternative policy options.
mpact of alternative policy options.
Typically, FLORES models combine biophysical aspects (crops, trees and so forth) with human socio-economics and decision-making at the household level.
Simile is used as the modelling environment for FLORES, since it has the required expressiveness for the complex modelling involved, the computational efficiency needed to run the highly-disaggregated models, and the intuitive user interface needed for a participatory modelling approach.
The aim of FLORES is to improve the livelihoods of the rural poor. It seeks to do this by developing tools to enable those responsible for formulating policy to explore the possible impacts of alternative policy options.
FLORES is a user-oriented framework for rigorously exploring alternatives that can be calibrated to various situations, and tested against empirical data. It is implemented as a participatory modeling process that has a simulation model as an outcome of each iteration.
FLORES is built on the notion that there is no need to reinvent the wheel, existing knowledge is explicitly incorporated, integrated and acknowledged through the use of participatory modeling and a growing library of easily interchangeable sub-models.
Why was Simile chosen for FLORES modelling?
Simile was chosen for the implementation of FLORES because it was considered to meet a larger number of the requirements of FLORES than other candidate approaches.
- The fact that it is a visual modelling environment increases the extent to which various contributors to FLORES development (ranging from anthropologists and economists to crop and forest modellers) can participate in the process of model construction and interpret the model design decisions made by others.
- Its ability to handle basic System Dynamics concepts (stocks, flows, intermediate variables) makes it straightforward to implement the many standard biophysical models cast in these terms.
- It has powerful features for representing the complex disaggregation, object-orientation and relationships required for FLORES: multiple patch objects, dynamically-varying numbers of households, households nested inside villages, and tenure relations between households and patches.
- It can generate highly-efficient implementations of complex models (in compiled C++), essential for a model intended to deal with the interactions within and between hundreds of households and thousands of patches.
- Its support for modular modelling means that separate groups can develop submodels, which can then be combined to make a composite model.
- All output displays are customisable (through programming in the interpreted scripting language, Tcl/Tk), making it possible to engineer interfaces to GIS and displays specific to the requirements of FLORES.
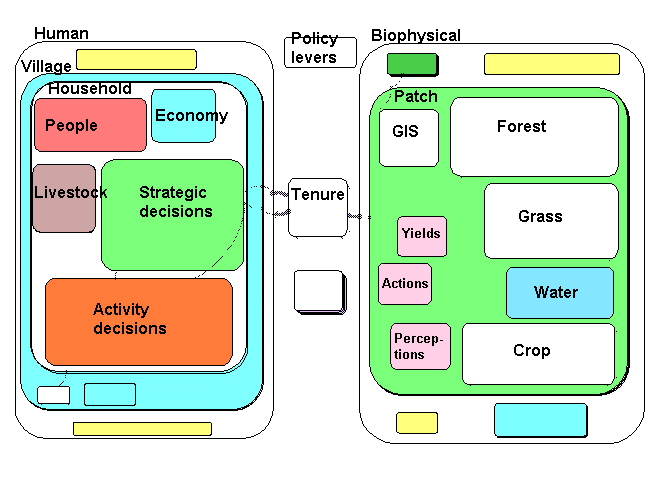
FLORES models typically have the following architecture:
- Human interactions, or the “left hand side” of the model. Here we find the human dimension of the landscapes we are interested in. Elements of this side of the model can range from individuals to districts. They are usually nested to reflect hierarchy concepts.
- Patches of landscape, or the “right hand side” of the model. These are the biophysical elements of the landscape. Each patch will have a unique identity (e.g. a polygon in a GIS) with its own characteristics. Thus it might carry a crop, grassland, forest or woodland, a fallow, etc. It can change its form of vegetation through dynamic interaction with neighboring patches and the human side of the model.
- Tenure relationships, the bridge between the left and right hand side of the model. Here we can link households uniquely to the patches of land they own, share, have access to, or are excluded from.
- Policy levers for changing model inputs. Usually placed at the top of the model diagram, these are variables that reflect external interventions (such as a subsidy for fertilizers) or scenario variables, such as a drought.
- Indicators are the means by which we can study this response. Usually placed at the bottom of the model diagram they can be defined as any variable in the model.
FLORES links
- A Symposium on Participatory Modelling, held in Harare, Feb 2002, included several papers on FLORES modelling.
- Volume 2 of the journal Small-scale Forest Economics, Management and Policy is a special issue on participatory modelling, and includes papers describing the Zimbabwe FLORES model, the Cameroon FLORES model, and the modelling of human decision-making in FLORES models.
- A web-based Powerpoint presentation on FLORES describes the motivation for FLORES, and the concepts on which it is based.
ZimFLORES: FLORES model developed for the Mafungausti State Forest, Zimbabwe
The Mafungautsi State Forest is located in central Zimbabwe, near the town of Gokwe. Considerable numbers of people live next to the forest, and there is considerable pressure to exploit the forest resources: primarily fuel wood, poles for construction, and grass for thatch in the vlei (annually-flooded river beds).
|
CIFOR has been undertaking research in the area for a number of years, concentrating on the relationship between the people, the forest resources, and the Forestry Commission, as part of the ACM project. They decided to take a lead role in developing a FLORES model for this context, based on a several villages on the north-west margin of the forest for which they had socio-economic data. The model was based on an earlier version of the FLAC training model, adapted by the addition of crop and water submodels on the biophysical side, and the development of a novel strategic decision-making submodel. The process of adapting the training model was undertaken with outside assistance, primarily in four FLAC workshops held between Sept 2000 and February 2001, in response to design requirements specified locally. The model was further refined in April 2001 as a demonstrator for the World Bank Rural Week meeting, held in Washington DC, 23-26th April 2001. |
Acronyms and Links ACM: the CIFOR-led Adaptive Co-Managament project CGIAR: Consulatative Group for International Agricultural Research, an umbrella organisation for a number of international institutes concerned with agriculture and natural resources. CIFOR: the Centre for International Forestry Research, a CGIAR centre FLAC: The FLORES Local Adaptation and Calibration package, which aims to enable local groups to make their own FLORES models. FLORES: Forest Land-Oriented Resource Envisioning System, an international programme concerned with modelling the interaction between people and their land resources at the forest margin. |
Structure
The overall structure of the model is shown in the submodel diagram, which was taken directly from the Simile implementation of the model.
The model conforms closely to the standard FLORES model, with a left-hand Human component and a right-hand Biophysical component. Inside the human submodel three villages are represented, with each village containing a variable number of households. The number of households increases when a family moves into the area, and decreases when a household dissolves because of, for example, the death of the only male adult. The biophysical side is represented in terms of a large number (900+) patches, based on the digitisation as polygons of the field boundaries from an aerial photograph.
The dynamics and behaviour of each household is modelled in five submodels:
- The submodel People models the changing population dynamics within the household, as children are born and household members die. It does this using a compartment-flow approach for each of four classes: children, adult males, adult females and elderly people.
- The submodel Economy models the economic status of the household, in terms of a single currency (“dosh”, or daily ordinary subsistence per household), which puts all household resources on a common basis.
- The submodel Livestock represents the dynamics of the household’s herd of livestock. It is placed here, rather than in the Biophysical submodel, since each household has its own herd.
- The submodel Strategic decisions is responsible for determining each household’s lifestyle strategy. This is represented in terms of the relative priority given by the household over the coming year to each of seven activities (such as growing maize, growing cotton, or pole collection).
- The submodel Activity decisions is responsible for determining the household’s week-by-week decisions. These primarily relate to the allocation of the household's labour resources to various activities, but include non-labour decisions, such as choice of crop to plant and allocation of cattle to grazing land.
The dynamics on the biophysical side is modelled in terms of four components:
- The Forest submodel calculates the dynamics of the miombo woodland in the State forest land. It is based on a model developed prior to FLORES in a workshop held in Zimbabwe, and represents the forest in terms of the number of trees in each of four classes: gullivers, poles, medium trees and large trees. It includes the reversion of trees to earlier classes if there has been a fire.
- The Grass submodel is also based on one developed in the same workshop. Its main relevance is in providing grass for thatch, but it also has a role in cattle grazing.
- The Water submodel is used to influence the growth of grass, since occasional drought years have a major influence on the people and their livelihoods.
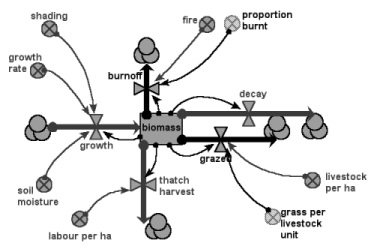
- The Crop submodel is rather special. Three types of crop are allowed for: a food crop (maize); a cash crop (cotton); and vegetables (home garden). Any one patch can have only one of these, and the allocation of a crop to a patch is determined in the strategic decision-making submodel of the household that owns the patch. The following diagram illustrates the generic crop model used.
The GIS submodel contains fixed patch-level attributes (e.g. area, soil type), as well as the boundary coordinates for display purposes.
Households and patches are joined by a Tenure association. This allows for two types of tenure: (1) ownership of a patch by a household; and (2) access to common land. The main role of the tenure association is to channel information flows from patch to household and vice versa. Three types of information are transferred:
- Perceptions carry information about the patches they own to the households that own them.
- Actions carry information on the households weekly decisions from household to the patches they own.
- Yields carry information on the amount of produce harvested from patches to the households that own them.
Using the model
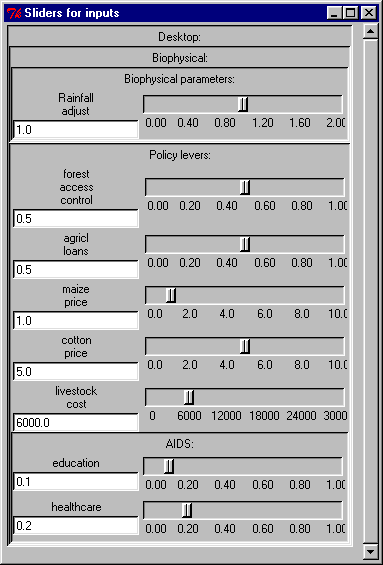
The model is set up with a Control Panel that enables you to set various policy options. You simply move the sliders and continue running or restart the model .
The behaviour of the model can be displayed using a number of display tools, including graphs and maps. T he following diagrams are for illustrative purposes.
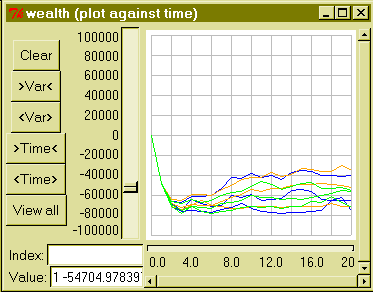
The two graphs below show how the model can be used to investigate how the community responds to changes in healthcare. The first shows the changes in the average number of adults per household in each of three villages. The orange lines show the standard run of the model. The blue lines reflect the effect of improved healthcare and health education: there is a slight improvement in the average household size. The green lines are for an increased incidence of AIDS: not a policy lever as such, but still something that the user of the model might wish to explore.
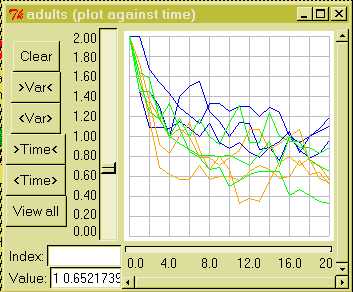
The following graph is for the same three cases, but shows wealth per household (in each of the three villages). No obvious effect of the healthcare/education policy is apparent, probably because a decrease in mortality is balanced by a decrease in resources per household.
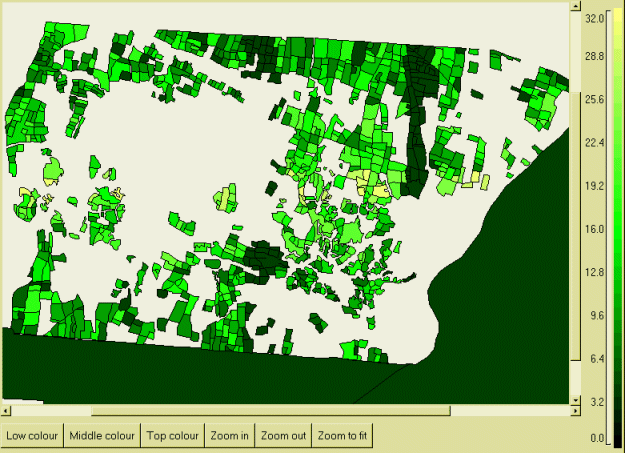
This map shows how indicators of performance can be displayed spatially. The solid dark area is part of the Mafungautsi State Forest. The small polygons are fields in the Batanai village: at the time this was prepared, only about half of the field boundaries had been digitised. The colour shows variations in crop productivity, with lighter areas indicating higher crop productivity running from left to right through the centre, with lower productivity on the higher (hence drier) land above and below this belt.
{kind=link}
References
- ZimFlores: A Model to Advise Co-management of the Mafungautsi Forest in Zimbabwe
- Modelling Decision-making in Rural Communities at the Forest Margin
ModMED: Modelling Mediterrean Ecosystem Dynamics
 ModMED was an international ecological research project studying vegetation dynamics in semi-natural vegetation of the Mediterranean region. The objective was to understand the behaviour of vegetation and to be able to construct predictive models that can be used in thefuture management of burning and grazing.
ModMED was an international ecological research project studying vegetation dynamics in semi-natural vegetation of the Mediterranean region. The objective was to understand the behaviour of vegetation and to be able to construct predictive models that can be used in thefuture management of burning and grazing.
ModMED was based on a GIS-based modelling system, for handling landscape-level processes such as water movement and seed dispersal, combined with a variety of alternative vegetation models at the patch level. Simile was used for developing the vegetation models.
Recent developments in agricultural policy and land use have resulted in major changes in the ecology of Mediterranean ecosystems. Changes in grazing patterns and fire frequency and intensity have been major contributing factors.
The ModMED project is concerned with the dynamics of vegetation in response to these changes. The relevant ecological processes at the landscape, community and individual levels are being researched in Italy, Portugal and Greece and represented in a hierarchical, modular modelling environment.
The ModMED modelling environment provides a powerful tool for scientific research into the ecology and management of semi-natural vegetation, and for decision making in resource management at regional and national levels. Simile has played an important role in developing models at the community and individual levels, for use by themselves and for incorporation into Landlord, ModMED’s landscape-level modelling framework.
The following sections illustrate some of the uses of Simile within ModMED. The examples are:
- a simple model of photosynthesis;
- a model of crown development, with the crown divided into horizontal layers and radial segments;
- a detailed model of multiple-species vegetation dynamics; and
- the integration of a model of seed production and dispersal in the landscape-level modelling framework.
For more information on the role of Simile in ModMED modelling, please consult the following two documents, which were extracted from the ModMED Final Report:
- Community level models (available as pdf, 1.62 MB)
- Integration between landscape and community models (available as pdf, 1.18 MB)
Please note that many people were involved in the ModMED project. A list of the principal participants is included in both of the above documents.
More information on ModMED can be found on the ModMED web site
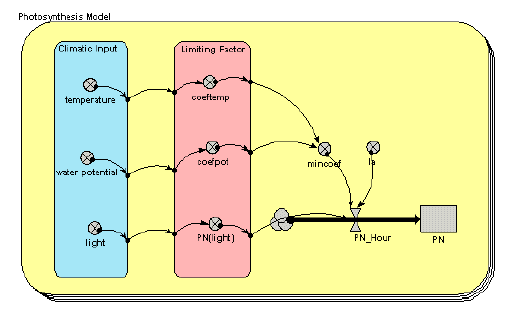
Photosynthesis model
This simple model uses three climatic inputs (temperature, water potential and light) to calculate net photosynthesis for each of several species. Note the use of a multiple-instance submodel (the round-cornered box, with multiple boundaries), with one instance for each species.
Tree crown model
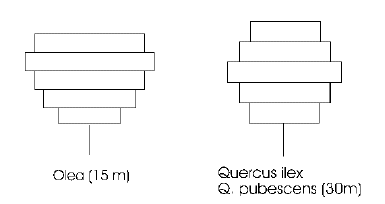
This model represents the canopy of each tree as a series of layers, with each layer divided into 16 segments. The layers allow typical species-specific crown profiles to develop: the two examples shown here are for olive and oak. The segments allow the horizontal extension of the canopy to be limited when it encounters a neighbouring tree.
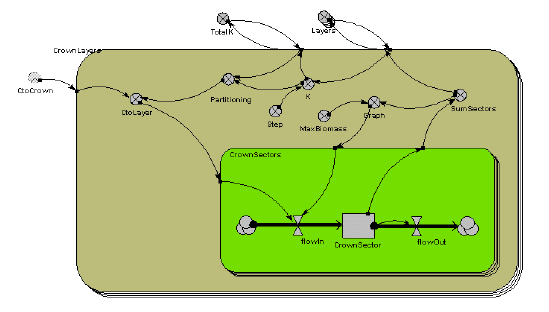
Below is the Simile model diagram for the crown of a single tree. You can see that it consists of two, nested, multiple-instance submodels. The outer submodel is for each crown layer. The inner submodel is for the 16 segments in each layer.
The crown model was in fact part of a larger, stand-level model, representing a collection of trees. In addition, the roots were also modelled, in terms of a series of root discs. In order to visualise the dynamics of the complete model, the Naples team that developed the model also developed a specialised display tool. This produces output in a 3D language called VRML, which allows the user to rotate, zoom and pan the image interactively. The following two screen shots show two views of the modelled stand of trees at some stage during the simulation, viewed from above and near ground level.

The root discs can be clearly seen in the latter view.

N-species vegetation dynamics
The preceding example shows one way in which the modelling of a vegetation component can be made more detailed – in that case, by disaggregating one component (the crown) into separate bits. This is appropriate for big, discrete vegetation components, such as trees. Another way of attempting to make a model more realistic is to model the processes themselves in more detail. The complete model diagram shows a multiple-species model of biomass dynamics developed using Simile in ModMED.
The multiple-boundary for the submodel SPECIES shows visually that several species are being modelled. Some components of the system (such as soil water balance and fire) are outside this submodel, indicating that they apply at the community level, rather than separately for each species.
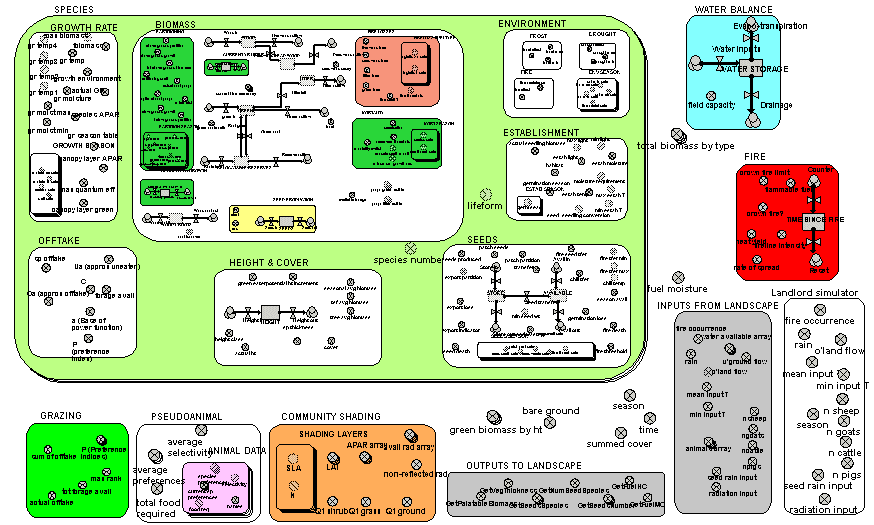
A zoomed-in view of the BIOMASS submodel enables the names of the individual variables to be seen.
In both diagrams, the influence arrows have been suppressed, for clarity. Simile allows users to choose which model diagram elements (including variables, flows and compartments) are displayed.
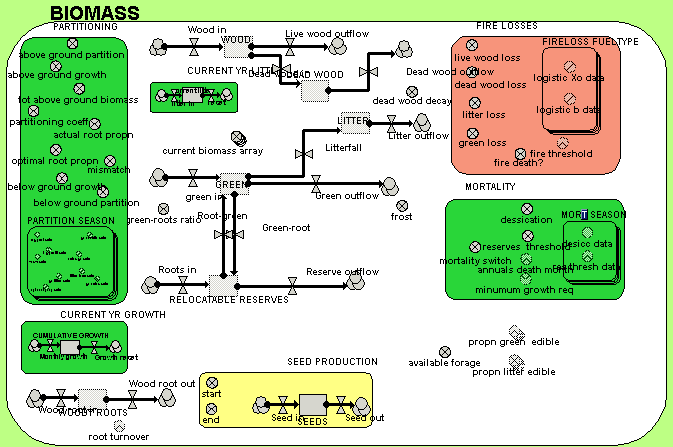
Seed dispersal using a GIS-based spatial modelling environment
Simile is capable of simulating both within-patch dynamics (e.g. vegetation dynamics) and between-patch dynamics (e.g. seed dispersal). However, Simile was introduced into the ModMED project in the third phase, after a GIS-based landscape-level modelling framework (called Landlord) had been developed. It was therefore decide to use Simile just for modelling at the patch (community) level, and to let LANDLORD manage seed dispersal, water movement and the spread of fire across the landscape.
This required that a Simile model could be incorporated into Landlord, and replicated across all the landscape grid cells. This was achieved by developing an interface which allowed the modeller to indicate the correspondence between variables in the Simile model and those in the landscape-level framework, and by generating a DLL for the Simile model which can be called by Landlord.
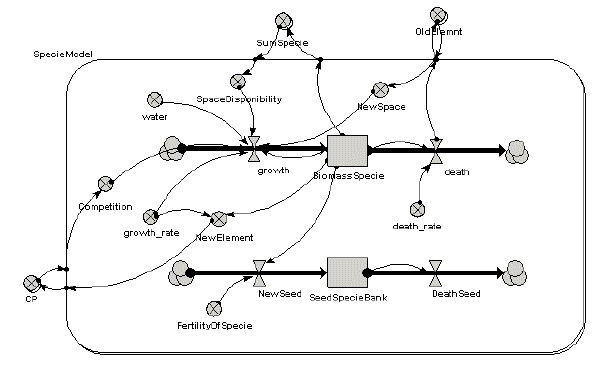
The following model diagram shows a simple biomass-based model of vegetation dynanics for several species. Note that it includes a seed production component.
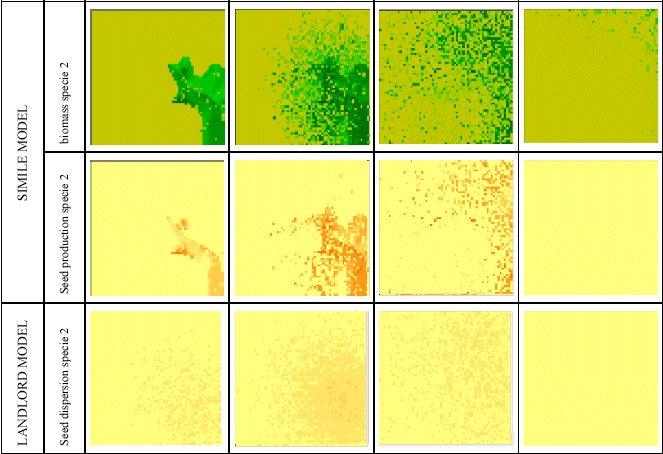
This model was then linked up to Landlord. These maps show the biomass and seed production simulated by the Simile model across all the grid cells of the landscape, at four points in time. The third row shows the seed dispersal calculated by Landlord, based on the seed production in each cell. This allows the vegetation to spread across the landscape over time.
Modelling the clinical and cost effectiveness of screening for MRSA in hospitals
Introduction
Staphylococcus aureus is a bacterium that many healthy people carry without it causing infection. However, if it enters the body, it can cause a range of illnesses from minor localised skin infections to systemic life-threatening illnesses.
Antibiotics are used to treat more serious staphylococcal infections but some strains of Staphylococcus aureus have developed resistance to commonly used antibiotics including meticillin. Meticillin-resistant Staphylococcus aureus (MRSA) is a major cause of healthcare-associated infection. Infections with MRSA are associated with greater risk of treatment failure, increased patient mortality, and high costs.
A number of hospital management strategies are available for reducing the prevalence of MRSA in hospitals. These include:
- Screening patients to identify MRSA carriers (referred to as 'colonised', meaning that they have the MRSA bacterium on their skin). Screening involves taking swabs from one or more body sites, followed by laboratory analysis of these samples.
- Decolonisation treatment for identified carriers
- Isolation, for identified carriers or pre-emptively.
In 2006, Quality Improvement Scotland, a specialist board within NHS Scotland, undertook a Health Technology Assessment (HTA) to evaluate "The clinical and cost effectiveness of alternative screening programmes for MRSA for patients admitted to hospital". The HTA involved the analysis of evidence from scientific literature, experts, professionals groups and patient interest groups. In addition, a modelling study was undertaken to assess the clinical and cost effectiveness of alternative screening strategies.
The model was implemented using Simile, with the initial model development undertaken within QIS. Simulistics, under contract from QIS, completed model development and provided support for the detailed analysis of model behaviour.
Modelling approach
The modelling approach is based on stock-and-flow modelling (commonly known as System Dynamics), in which a system is represented as a set of pools with flows into, out of and between them. In this case, the pools represent number of people.
In conventional System Dynamics, the stocks and flows represent the amount and rate-of-flow of some substance (e.g. water). These models generally involve values on a continuous scale (e.g. 10.357 litres), and are usually deterministic (you get the same result each time you run the same model).
It is not appropriate to model small numbers of individuals in this way. Therefore, this model has been engineered so that all the flows are in terms of whole (integer) numbers. Because of this, the model needs to use stochastic (probabilistic) methods to decide randomly whether the value of a flow will be 0, 1, 2 or 3 individuals if the mean rate is (for example) 1.357. The main method used is to sample from a binomial distribution, to generate a number of individuals given a population size n and a probability p of some event happening.
Description of the model
The model represents a single hospital and the community it serves. The following table sets out some of the assumptions used in the modelling process, and the corresponding realisation of these assumptions in the Simile model.
| Real-world assumptions | Representation in the Simile model | Simile diagram |
|---|---|---|
|
The people in the community may be colonised or uncolonised with MRSA (i.e. the bacterium is or is not present on their skin). They may have a low or high risk of being admitted to hospital, and they are in the under 65 or 65-and-over age group. People in the community may change their colonisation or risk-of-re-admission status. |
The community submodel contains a single, 2-instance submodel, one instance for each age group. Four compartments in the submodel represent the number of people in each colonisation and likelihood-of-admission class. E.g. the compartment HRR_U represents the number of people with a high risk of re-admission who are uncolonised. There are flows between each of these 4 compartments. |
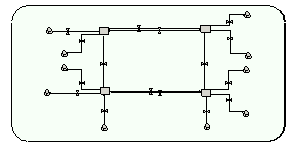
The community age-group submodel (2 instances, 1 instance for each age group). Left 2 compartments: uncolonised people; right: colonised. Top 2 compartments: low risk of re-admission; bottom: high risk. |
|
The hospital has 2 emergency wards and 34 speciality wards. 15 of the speciality wards are 'high risk', in that a patient has a higher risk of acquiring an MRSA infection while there. Within each ward, patients are either in the under 65 or 65-and-over age group. Within each ward, patients may be in one of several states with respect to their MRSA status, depending on whether they are known/not-known to be colonised/infected with MRSA. |
A single, 2-instance submodel is used for the emergency wards, and a single, 34-instance submodel is used for the speciality wards. Of these the first 15 instances have a value 'true' for the variable 'high-risk speciality'. Each of the 2 ward submodels contains an inner 2-instance submodel, one for each age group. Compartments are used within the ward submodels to represent the number of patients in each state, with flows to model the movement of patients between categories. |
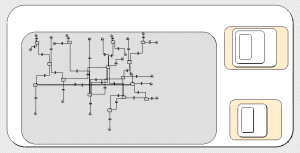
The speciality ward submodel (34 instances, since there are 34 wards). The inner grey submodel is for the 2 age groups. The compartments are for number of patients in different categories. The small nested submodels are for selecting admission to the wards and the isolation rooms respectively. |
|
Each ward may have 1 or more isolation rooms, to isolate patients according to their MRSA status. |
Two of the compartments in the ward submodel are used to represent the number of people in isolation rooms. |
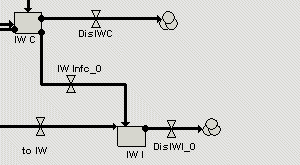
Close-up view of the isolation room compartments in each ward. "IW C" and "IW I" are the number of colonised and infected patients respectively in isolation rooms in the ward. |
|
Six screening strategies are considered (listed below this table). |
Each screening strategy is represented by a separate submodel. Each submodel contains a 'condition' symbol, and only the condition symbol for the currently-selected strategy is set to 'true'. Thus, for any one run, only one strategy is in operation, even though all 6 are represented in the model. Some of the strategies involve the use of "zero-valued compartments". These are compartments whose outflows always equal inflows. This approach is used to show the flow of patients through the system, even when there is no residency time at a particular stage - e.g. assessment by a health practitioner of a person's chance of being MRSA-colonised. |
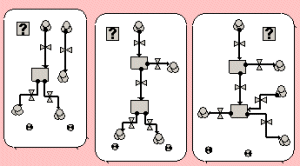
Three of the screening strategy submodels. The flow pathway shows the movement of people through the screening process. Note the use of the condition symbol [?] in each one, to ensue that only one strategy is in use at any one time. |
The six screening strategies
The 6 strategies represent alternative screening options for incoming patients. In summary, they are:
- Do nothing - treat all patients as uncolonised;
- Swab all patients to identify colonised individuals;
- Swab patients going for high-risk specialities - treat others as uncolonised
- Carriage assess all patients (i.e., assess their risk of colonisation from their clinical history) and swab those with a positive assessment. Treat others as uncolonised;
- Swab all patients going for high-risk specialities, carriage assess others and swab those with a positive assessment
- Swab all patients, also carriage assess them and treat those with positive assessment as colonised pending swab results.
Using the model
Data sources
The model requires a range of input values. These can be classified as follows:
- Management variables
These are factors over which management has some control. The model was constructed in order to explore the way the outputs of the model (the indicators of performance, see below) changed depending on different values for these inputs. The main one is screening strategy (one of the 6 listed above). Others include the number of isolation rooms in the emergency wards and the low-risk and high-risk speciality wards, and the effectiveness of decolonisation treatments in the different types of ward. - Domain parameters
These are parameters which relate to the specific hospital being modelled. These include the number of people in the community served by the hospital, and 'swab delay', the time it takes to get the results back for a swab test. - Estimated parameters
These relate to the biological and epidemiological properties of the system itself. These include:- the proportion of swab tests and carriage assessments which correctly identify colonised patients;
- the false-positive rate for these procedures;
- the spontaneous rate of decolonisation of colonised patients;
- cross-infection parameters - probability of one patient becoming colonised through the presence of another.
Settling-in period
For any one scenario, there is a lack of detailed information on the number of MRSA-colonised people in the hospital and the community it serves, in each of the various categories. To overcome this, the model starts off with an empty hospital and the default management strategy, and runs for 3000 days, giving equilibrium numbers which correspond to observed figures. The run then continues with the chosen strategy switched on.
Running the model
Interactive use
During development, the model is run in Simile's usual interactive environment. This allows rapid interaction between the model-design process and test runs of the model.
Batch-mode use
However, analysis of the model's behaviour requires a large number of runs to be performed. This is partly because there are a wide range of management scenarios to be investigated, but mainly because the model is stochastic (probabilistic). This means that the results obtained from two runs will be different, because of chance effects in the model, even when all the inputs are identical. For these purposes, use is made of Simile's scripting environment, which enables a model to be run under control of a script. The script can set the inputs to a model run, control the number of times the model is run for any one set of inputs, and collate the results of many runs for subsequent analysis.
Results
Single runs
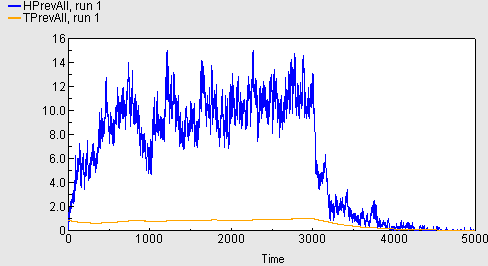
Prevalence of MRSA
The following graph shows the prevalence of MRSA (percentage of people colonised) in the community (red) and the hospital (blue). You can clearly see the transition from the run-in period of 3000 days, with no MRSA management strategy in place, to the introduction of the management strategy used in this run.
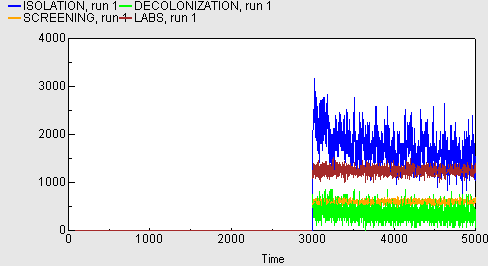
Costs associated with MRSA control measures
The following graph shows the costs associated with the introduction of MRSA control measures. These only apply after the 3000-day run-in period, and are broken down into costs associated with screening (orange), isolation of patients (blue), decolonisation treatments (green) and running labs (brown).
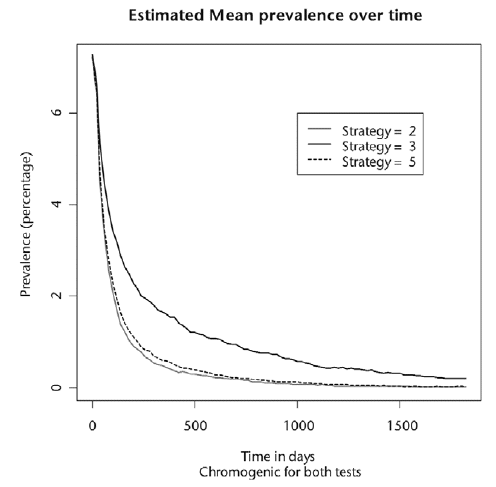
Aggregate results (batch-mode runs)
The results from batch-mode runs were exported to a spreadsheet and analysed in terms of MRSA prevalence and costs of various strategies. The following figure is an example (taken from the Health Technology Assessment report). It shows the prevalence of MRSA in the hospital under 3 strategies for 2000 days following the introduction of the specified strategy.
Links
NHSScotland /Quality Improvement Scotland: HTA 9: The clinical and cost effectiveness of screening for meticillin-resistant Staphylococcus aureus (MRSA)
Main page pdf 1.44MB (See chapter 6: "Economic Evaluation and Modelling")
Accessing the model
A zipped file containing the model plus associated files is attached to this page. To use the model, unzip the file onto your own computer, start Simile, and load the model file (TRH_2008_model_package.sml). Simile should open up the RunTime window. Click on the Start button (the right-facing triangle, like the play button on a CD player) to run the model. Press it several more times to continue running the model.
28 September 2010 The attached file (TRH_2008_packageSimile.zip) has been updated to build and run in Simile 5.7 with no warning messages. (Better compatibility checking in Simile 5.7 flagged a comparison of an enumerated type with its corresponding representation as an integer. Full use of enumerated types makes the model easier to read.)
The model should run in the free Evaluation Edition of Simile, available from http://www.simulistics.com/products/simile.php. If you already have Simile, you may need to upgrade to the most recent version (currently Simile 5.3) to run this model.
| Attachment | Size |
|---|---|
| 1.78 MB |